
Authors:
(1) Aviad Rom, The Data Science Institute, Reichman University, Herzliya, Israel;
(2) Kfir Bar, The Data Science Institute, Reichman University, Herzliya, Israel.
Table of Links
3. Methodology
We begin by pre-training a new language model using texts written in both Arabic and Hebrew. This model, named HeArBERT, is subsequently finetuned to enhance performance in machine translation between Arabic and Hebrew.
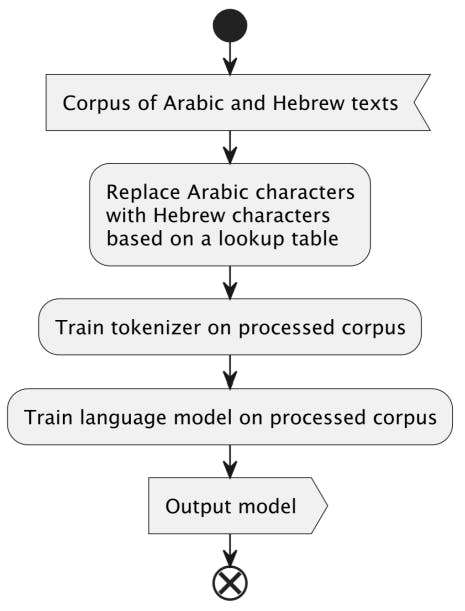
For pre-training, we utilize the de-duplicated Arabic (∼3B words) and Hebrew (∼1B words) versions of the OSCAR dataset (Ortiz Suárez et al., 2020). In this work, we aim to measure the impact of normalizing all texts to a shared script, so that cognates can be unified under the same token representation. Therefore, we transliterate the Arabic texts into the Hebrew script as a preprocessing step for both training and testing. Our transliteration procedure is designed following most of the guidelines published by The Academy of the Hebrew Language who has defined a Hebrew mapping for every Arabic letter[4], and the mapping provided in (Terner et al., 2020). Only Arabic letters are converted to their Hebrew equivalents, while non-Arabic characters remain unchanged. Our implementation is based on a simple lookup table, executed letter by letter, which is composed of the two mappings mentioned above, as shown in Appendix A.
For evaluation, we independently train the model twice: once with the transliteration step and once without. We subsequently compare the performance of these two versions when fine-tuned on a downstream machine translation test set.
Our model is based on the original BERT-base architecture. We train a WordPiece tokenizer with a vocabulary size of 30, 000, limiting its accepted alphabet size to 100. This approach encourages the learning of tokens common to both languages, allowing the tokenizer to focus on content rather than on special characters not inherent to either language. We choose to train only for the masked language model (MLM) task employed originally in BERT, ignoring the next-sentence-prediction component, as it has previously been proven less effective (Liu et al., 2019). Overall, we trained each model for the duration of 10 epochs, over the course of approximately 3 weeks, using 4 Nvidia RTX 3090 GPUs.
Fine-tuning HeArBERT is done similar to finetuning the original BERT model, except for the addition of the transliteration step of Arabic letters that takes place prior to tokenization. In this preprocessing step, all non-Arabic letters remain intact, while Arabic letters are transliterated into their Hebrew equivalents, as described above.
The preprocssing and pre-training process of HeArBERT is depicted in Figure 1
This paper is available on arxiv under CC BY 4.0 DEED license.
[4] https://hebrew-academy. org.il/wp-content/uploads/ taatik-aravit-ivrit-1.pdf