
Authors:
(1) Aviad Rom, The Data Science Institute, Reichman University, Herzliya, Israel;
(2) Kfir Bar, The Data Science Institute, Reichman University, Herzliya, Israel.
Table of Links
5. Results
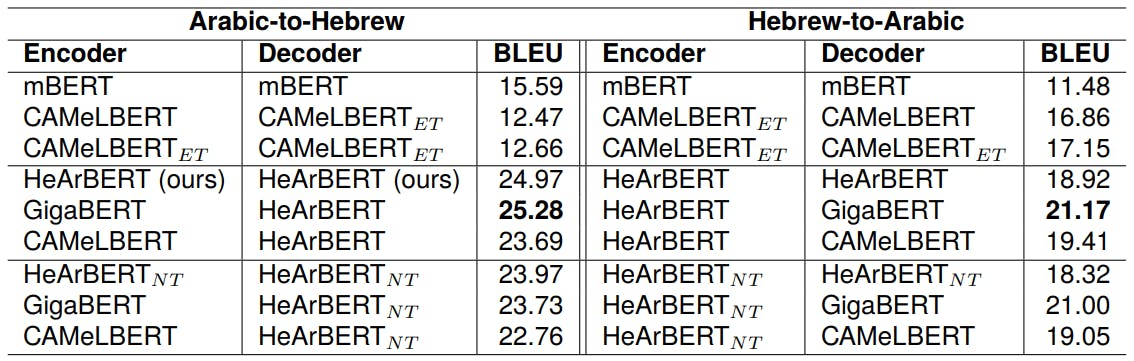
The results are summarized in Table 1. The table rows are organized into three distinct groups. The first group features combinations of various baseline models. The second group showcases combinations incorporating our proprietary HeArBERT model, while the third group highlights combinations involving the contrasting HeArBERTNT model. We train multiple machine-translation combinations, in both directions Arabic-to-Hebrew and Hebrewto-Arabic, based on the same encoder-decoder architecture, initialized with different language model combinations. We assign various combinations of language models to the encoder and decoder components, ensuring that the selected models align with the respective source and target languages. In other words, we make sure that the language
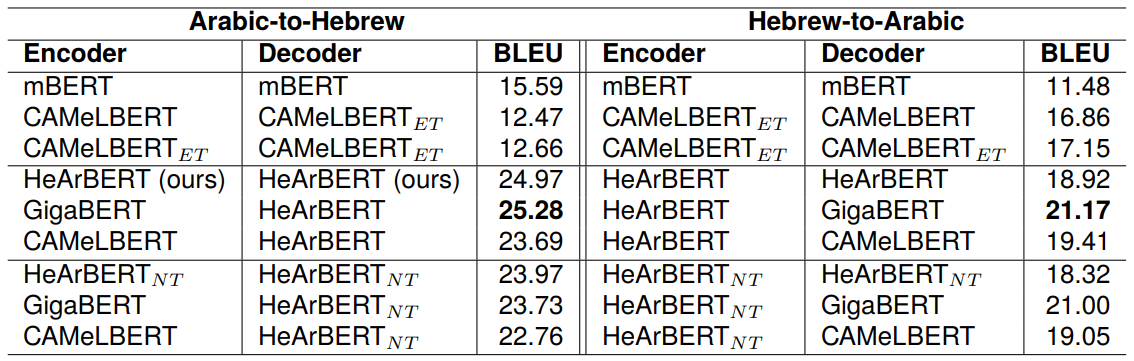
model which we use to initialize the encoder, is compatible with the system’s source language.
Since mBERT and CAMeLBERTET , as well as our two models HeArBERT and HeArBERTNT , can potentially handle both languages, we experiment with combinations where each of them is assigned to both, the encoder and decoder components at the same time.
The results demonstrate that the second group, which utilizes our HeArBERT to initialize a Hebrew decoder, surpasses the performance of all other combinations. Notably, the pairing of GigaBERT with HeArBERT is the standout performer across both directions. It surpasses the performance of using HeArBERT for initializing the Arabic encoder by only a few minor points. The performance of HeArBERTNT , as reported in the third group is consistently lower than HeArBERT in both directions. The difference seems to be more significant in the Arabic-to-Hebrew direction. Overall, the results show that transliterating the Arabic training texts into the Hebrew script as a pre-processing step is beneficial for an Arabic-to-Hebrew machine translation system. The impact of the transliteration proves to be less pronounced in the reverse translation direction.
Using the extended (ET) version of CAMeLBERT has a reasonable performance. However, it performs much worse than the best model in both directions, indicating that extending the vocabulary with transliterated Arabic tokens does contribute to better capturing the meaning of Hebrew tokens in context. This implies that joint pre-training on both languages is essential for achieving a more robust language representation.
This paper is available on arxiv under CC BY 4.0 DEED license.